システム開発でChatGPTを利用できるシーン & 使いこなせる人の特徴とは?
- 土門 大貴
- 記事制作日2023年5月29日
- 更新日2023年10月21日

- 1いいね!

システムエンジニアの皆様、ChatGPTは使われていますか?
色々な理由で躊躇されている方も少なくないようですが、テキストベースでしかやり取りできない『ノーマルのGPT-4』でも、システム開発においては十分役に立ちます。
この記事では、実際にChatGPTを使ってどのようなプログラムを作れるのか、またChatGPTを使いこなせる人はどのような人なのか、といった点を取り上げます。
対象読者
- ChatGPTを利用してサクサク開発を行いたいエンジニア
- 開発スピードが遅くて困っているマネージャー職の方
- とにかく早くIT製品を開発したい事業会社様
- ChatGPTを使うとエンジニアはどうなる?と思っている経営者
パイソンでURLを指定して画像ファイルをダウンロードするための簡単なコードは以下の通りです。この例ではrequestsライブラリを使用します。もしまだインストールしていない場合、ターミナルからpip install requestsでインストールすることができます。
import requestsdef download_image(url, filepath): response = requests.get(url, stream=True) if response.status_code == 200: with open(filepath, 'wb') as file: file.write(response.content) else: print("Unable to download image. HTTP response code: ", response.status_code)# 使い方url = "http://example.com/image.jpg" # ダウンロードする画像のURLfilepath = "/path/to/save/image.jpg" # 画像を保存するファイルパスdownload_image(url, filepath)このスクリプトは指定したURLから画像をダウンロードし、指定したファイルパスに保存します。HTTPステータスコードが200(リクエストが成功した)場合にのみファイルを保存します。それ以外のステータスコードが返された場合は、エラーメッセージを表示します。
ただし、特定のウェブサイトは直接的な画像ダウンロードを許可していないことがあります。その場合、このコードは機能しない場合があります。必ずしも全てのウェブサイトに対して有効であるとは限らないことに注意してください。
そこそこいい感じのコードが出てきましたが、意図していたのは『ページ内全ての画像をダウンロードするプログラム』でした。
なので、以下のように指示を出し直します。
『URLに複数の画像ファイルがある場合、自動でHTMLファイルにある画像URL一覧を取得して、全ての画像をダウンロードしたいです』
その場合、requestsとBeautifulSoupを使用してHTMLから画像のURLを抽出し、それぞれダウンロードすることができます。以下に一例を示します。BeautifulSoupをまだインストールしていない場合、ターミナルからpip install beautifulsoup4でインストールできます。
import osimport requestsfrom bs4 import BeautifulSoupdef download_image(url, filepath): response = requests.get(url, stream=True)if response.status_code == 200: with open(filepath, 'wb') as file: file.write(response.content) else: print("Unable to download image. HTTP response code: ", response.status_code)def get_all_images(url): soup = BeautifulSoup(requests.get(url).text, "html.parser") urls = [] for img in soup.find_all("img"): img_url = img.attrs.get("src") if not img_url: continue if 'http' not in img_url: img_url = f"{url}{img_url}" urls.append(img_url) return urls# URLにあるすべての画像をダウンロードurl = "http://example.com" # 画像をダウンロードするウェブサイトのURLimage_urls = get_all_images(url)for i, img_url in enumerate(image_urls): download_image(img_url, f"path/to/save/image_{i}.jpg")このスクリプトは指定したURLから画像をダウンロードし、指定したファイルパスに保存します。HTTPステータスコードが200(リクエストが成功した)場合にのみファイルを保存します。それ以外のステータスコードが返された場合は、エラーメッセージを表示します。
ただし、特定のウェブサイトは直接的な画像ダウンロードを許可していないことがあります。その場合、このコードは機能しない場合があります。必ずしも全てのウェブサイトに対して有効であるとは限らないことに注意してください。
そこそこいい感じのコードが出てきましたが、意図していたのは『ページ内全ての画像をダウンロードするプログラム』でした。
なので、以下のように指示を出し直します。
『URLに複数の画像ファイルがある場合、自動でHTMLファイルにある画像URL一覧を取得して、全ての画像をダウンロードしたいです』
その場合、requestsとBeautifulSoupを使用してHTMLから画像のURLを抽出し、それぞれダウンロードすることができます。以下に一例を示します。BeautifulSoupをまだインストールしていない場合、ターミナルからpip install beautifulsoup4でインストールできます。
import osimport requestsfrom bs4 import BeautifulSoupdef download_image(url, filepath): response = requests.get(url, stream=True) if response.status_code == 200: with open(filepath, 'wb') as file: file.write(response.content) else: print("Unable to download image. HTTP response code: ", response.status_code)def get_all_images(url): soup = BeautifulSoup(requests.get(url).text, "html.parser") urls = [] for img in soup.find_all("img"): img_url = img.attrs.get("src") if not img_url: continue if 'http' not in img_url: img_url = f"{url}{img_url}" urls.append(img_url) return urls# URLにあるすべての画像をダウンロードurl = "http://example.com" # 画像をダウンロードするウェブサイトのURLimage_urls = get_all_images(url)for i, img_url in enumerate(image_urls): download_image(img_url, f"path/to/save/image_{i}.jpg")このスクリプトは指定したURLのページをスクレイピングし、imgタグが見つかったらそのsrc属性(つまり、画像のURL)を取得します。そして、それぞれの画像をダウンロードします。ダウンロードした画像は image_0.jpg, image_1.jpg, image_2.jpg ...という形で保存されます。
なお、これらのコードは一部のウェブサイトでしかうまく動作しないことがあります。画像のURLが相対パスで指定されているか、絶対パスで指定されているかによっては、適切に動作しない場合があります。また、一部のウェブサイトではスクレイピングを禁止している場合もありますので、利用するウェブサイトの利用規約等を確認することをお勧めします。
普通に使えるコードが出てきましたね。
しかし最近多くのサイトでlazy load等の遅延読み込み等を行っているため、このままでは取得できないサイトもあります。
簡単なコードの追加であれば、ここから自分で修正してもいいのですが、
せっかくなのでここもChatGPTに任せてしまいましょう。
『lazy loadにも対応させたい』
ウェブサイトによっては、画像の読み込みを遅延させる(lazy load)というテクニックを使用している場合があります。これは、ウェブページのパフォーマンスを向上させるための一般的な手法で、ページが初めてロードされたときに全ての画像をロードする代わりに、画像がビューポートに近づいたときにのみロードします。
Pythonのスクレイピングツールの中には、JavaScriptを実行してページのダイナミックな要素を読み込むことができるものもあります。そのようなツールを使用すれば、lazy loadされる画像をダウンロードすることも可能です。
その一例としてSeleniumを使用する方法を紹介します。まずはSeleniumと、それを動かすためのWebドライバ(ChromeならChromeDriver、FirefoxならGeckoDriver)をインストールする必要があります。その上で以下のようにコードを書くことで、JavaScriptが実行された後のページ内容から画像を取得することができます。
import osimport timefrom selenium import webdriverfrom bs4 import BeautifulSoupdef download_image(url, filepath): response = requests.get(url, stream=True) if response.status_code == 200: with open(filepath, 'wb') as file: file.write(response.content) else: print("Unable to download image. HTTP response code: ", response.status_code)def get_all_images(driver, url): driver.get(url) time.sleep(5) # Allow JS to execute and load images soup = BeautifulSoup(driver.page_source, "html.parser") urls = [] for img in soup.find_all("img"): img_url = img.attrs.get("src") if not img_url: continue if 'http' not in img_url: img_url = f"{url}{img_url}" urls.append(img_url) return urls# WebDriverのパスを指定(この例ではChromeを使用)driver_path = "/path/to/chromedriver"driver = webdriver.Chrome(executable_path=driver_path)# URLにあるすべての画像をダウンロードurl = "http://example.com" # 画像をダウンロードするウェブサイトのURLimage_urls = get_all_images(driver, url)for i, img_url in enumerate(image_urls): download_image(img_url, f"path/to/save/image_{i}.jpg")driver.quit()このコードでは、Selenium WebDriverを使用してページを開き、JavaScriptが実行されるのを待つことでlazy loadされる画像を取得します。
ただし、Seleniumを使用するとブラウザが実際に起動してページを開き、JavaScriptを実行しますので、リソースをかなり消費します。また、動的にコンテンツを生成するウェブサイトに対しては適切な待機時間を設定待機時間を設定することで、ウェブサイトの全てのコンテンツがロードされるのを確認することが重要です。上記の例ではtime.sleep(5)を使用していますが、これはウェブサイトによっては十分な時間でない場合があります。適切な待機時間を見つけるためには試行錯誤が必要な場合があります。
また、注意点としてSeleniumはウェブブラウザを操作するツールであるため、その使用はCPUとメモリを大量に使用します。したがって、リソースの制限がある環境では注意が必要です。また、ウェブサイトによっては頻繁なスクレイピングをブロックする場合がありますので、その点も留意してください。
さらに、これらの方法でダウンロードできる画像は公開されているものだけで、著作権やウェブサイトの利用規約に違反しないように注意しなければなりません。
最後に、Seleniumの代わりにHeadless ChromeやPhantomJSを使用することも可能です。これらのツールはブラウザのGUIを必要とせずにJavaScriptを実行することができますが、同様のリソースを消費する可能性があります。適切なツールを選択するためには、具体的な使用状況と必要な機能を考慮することが重要です。
コードを書いてくれただけでなく、詳しいアドバイスまでしてくれました。
非常に親切ですね。
GPT-3が出た当初は、まだ複雑なコードは難しいかな……、という品質でしたが、GPT-4は割りと実用性の高いコードをガンガン書いてくれます。
他にも『こういったコードは使える』といった例を取り上げます。
2.Bootstrap、TwailwindCSS、UIKitなどの最もポピュラーなフレームワークを使ったサンプル画面作成
例えば以下のような質問をします。
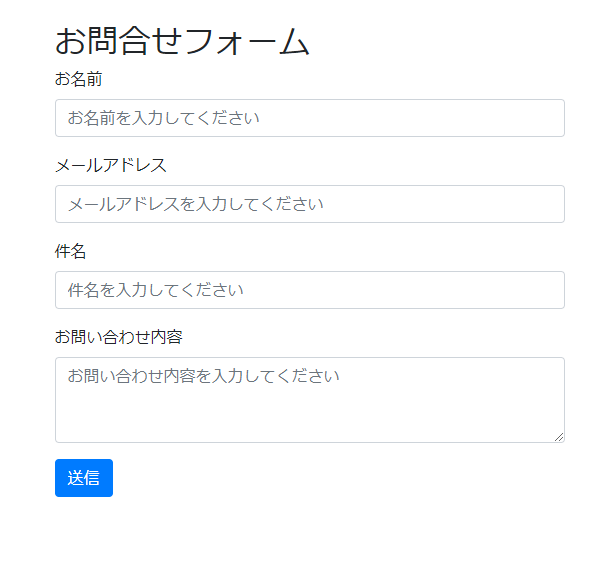
『Bootstrapでお問合せフォームを作ってください。項目は「お名前」「メールアドレス」「件名」「お問い合わせ内容」「送信ボタン」です』
(コードのみ抜粋します)
<!DOCTYPE html><html lang="ja"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>お問合せフォーム</title> <!-- Bootstrap CSS --> <link href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css" rel="stylesheet"></head><body> <div class="container"> <h2 class="mt-4">お問合せフォーム</h2> <form> <div class="form-group"> <label for="name">お名前</label> <input type="text" class="form-control" id="name" placeholder="お名前を入力してください"> </div> <div class="form-group"> <label for="email">メールアドレス</label> <input type="email" class="form-control" id="email" placeholder="メールアドレスを入力してください"> </div> <div class="form-group"> <label for="subject">件名</label> <input type="text" class="form-control" id="subject" placeholder="件名を入力してください"> </div> <div class="form-group"> <label for="message">お問い合わせ内容</label> <textarea class="form-control" id="message" rows="3" placeholder="お問い合わせ内容を入力してください"></textarea> </div> <button type="submit" class="btn btn-primary">送信</button> </form> </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.2.1.slim.min.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js"></script> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js"></script></body></html>実際にhtml化したものが下記になります。
ちゃんと「お問い合わせ内容」だけtextareaにしてくれていますね。

3.プログラミングでド忘れてした時にちょっとした問い合わせ
検索しようとすると、無駄にややこしい回答が集まってしまう質問も、ChatGPTなら的確に返してくれます。
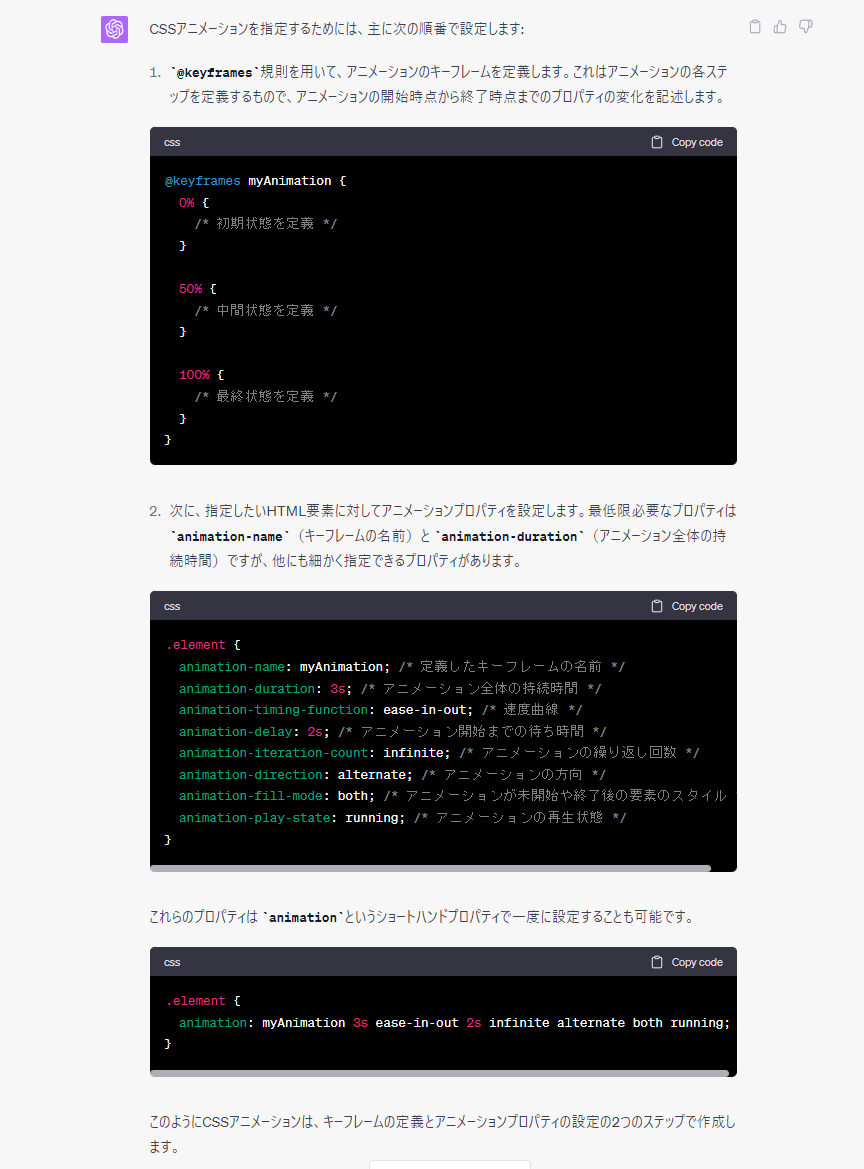
『CSSのanimationって何をどの順番で指定するんだった?』
※興味深い回答という訳でもないので、画像で貼り付けます。
4.既に作った機能をより分かりやすく一般的にする時の指標
例えば最初に出したコードについてですが、以下のように質問することで一般的にすることができます。
『一般的な画像のダウンロードをするpythonの関数を作成してください』
import requestsfrom typing import Optionaldef download_image(url: str, save_path: str, file_name: Optional[str]=None) -> None: """ Download an image from the provided URL and save it to the specified directory. Args: url (str): The URL of the image to download. save_path (str): The directory where the image will be saved. file_name (Optional[str], optional): The name of the saved file. If not provided, the name will be derived from the url. """ if file_name is None: file_name = url.split("/")[-1] response = requests.get(url, stream=True) if response.status_code == 200: with open(f"{save_path}/{file_name}", 'wb') as file: file.write(response.content) else: print("Unable to download image. HTTP response code: ", response.status_code)英語ではありますが、コメントまで付けてくれています。
5.広く普及している技術や考え方を確認する
要点を知りたいだけなのに、検索すると無駄に情報が細かくて難儀する疑問点というのは、時々ありますよね。
そんなときもChatGPTと会話することで解決することができます。
『HTTPとHTTPSの違いを、ユーザー目線で端的に教えて』
HTTP(HyperText Transfer Protocol)とHTTPS(HyperText Transfer Protocol Secure)は、インターネット上のデータを送受信するためのプロトコル、つまり規約です。この二つの主な違いは、「セキュリティ」にあります。HTTP:これはウェブサイトとユーザーの間で情報をやり取りする基本的なプロトコルです。しかし、HTTPは暗号化されていないため、サーバとクライアント間で交換される情報は第三者によって盗聴や改ざんが可能です。
HTTPS:これはHTTPにセキュリティを追加したものです。HTTPSはSSL/TLSというプロトコルを使用して、ユーザーとウェブサイト間の通信を暗号化します。これにより、データが盗聴や改ざんされるリスクを大幅に低減します。
ユーザー目線では、HTTPSが提供するセキュリティは、パスワードやクレジットカード情報などの重要な情報を送信する際に特に重要です。ウェブブラウザでは、HTTPSが使われているサイトは鍵のアイコンや緑色の表示で示され、これによりサイトが安全であることが確認できます。だから、ユーザーとしては、特に重要な情報を扱う際にはHTTPSを使用しているサイトを選ぶことが重要です。
ChatGPTを利用できないシーン

逆に、ChatGPTには向かない・あまり使用しないほうがいいシーンも存在します。
以下に例をいくつか取り上げます。
1.要件定義
『GPT-4』などは、すでに意思を持っているように見えることがありますが、実際には意思も思考もしておらず、『言語の関数近似器』でしかありません。なので『気を使う』とか『本当の問題点を把握する』といったことはできません。
例えば『あらゆる飲食物を扱うECサイト』の要件定義をChatGPTに指示してみましょう。
私も試してみたところ、『ユーザー管理機能』や『カート機能』『決済機能』等、数多くの要素を出してくれていますが、
『アルコールを販売する場合、年齢確認機能を表示する』といった要件は出てきませんでした。
このままお酒を売れば、二十歳未満の者の飲酒防止に関する表示基準に違反することとなります。
『アルコールの販売について指示していないのだから、それは出てこないに決まっている!』と思うかもしれませんが、
そういった事情・可能性を汲むのも要件定義の大事な責務です。
少なくとも、現時点では人間が要件定義を行ったほうが良いでしょう。
2.方式設計
これも先の点と重なりますが、
ChatGPTは『なにかあったときの想定』を細かく行ってくれませんし、責任も取ってくれません。
データベースが壊れた場合の予備や、ハードウェアに故障があった際の保全等、ChatGPTがアドバイスをくれることはあるかもしれませんが、細かなリスク管理は今でも人間に任せたほうがいいでしょう。
3.バックエンドやインフラ関連の設定手順
バックエンド部分やインフラ関連の設定・メンテナンスは、1つ手順を間違えただけで、取り返しのつかなくなるトラブルが起きたりします。
『ロードバランサの設定手順を教えて』とAIに聞いたとしても、返ってくるのは『一見出来てるように見える誤った手順』です。
こういった精密さの求められる作業は、信頼できるマニュアルを頼りましょう。
4.プログラミングを書いたことない人が学習に使う
ChatGPTはだいぶ『使えるコード』を書くようにはなってきましたが、いつでも『完璧なコード』を書いてくれるわけではありません。
普通に間違えますし、不適切なコードを出してくることも珍しくないです。
プログラミングを書いたことがない場合、そういったコード内の『誤り』『不適切な箇所』といったものを見分けられず、そのまま間違って覚えてしまうリスクがあります。
また、秩序立てて組んでいる訳ではないため、処理の短縮等も平気で行ってきます。
もしあなたがプログラミングを勉強中なのであれば、もっと体系立てて作られた『教育用のコード』に触れたほうが良いでしょう。
AIに触れるのは、ある程度実践を経てからでも遅くはありません。
5.最近新しく公開されたプログラミング言語や製品の情報
今この記事を執筆した時点で、GPT-4の最終学習日は2021年9月となっています。
なので、それ以降に公開された言語や製品について、GPT-4は詳細な情報を持っていません。
質問をしても『申し訳ありませんが、私の最終学習日は2021年9月までであり、その時点では「○○」に関する具体的な情報は提供されていません。このため、特定の設定手順を提供することはできません』という定型文が返ってきます。
また、それ以前に公開されていた言語・製品だとしても、学習に使える情報が不足している場合、ChatGPTの正確さは著しく低下します。
そういう場合も、ChatGPTに頼るより、googleやSNSでの検索を行って情報収集したほうがいいでしょう。
ChatGPTを使いこなせる人の特徴
ここまでChatGPTを開発で使う例・使わない方がいい例について取り上げましたが、
個人的には、エンジニアが『ChatGPTを使うこと』自体のスキルが必要だと思っています。
もしこれから『ガンガンChatGPTを開発で使いたい!』と思っているのであれば、以下のようなスキルを身につけることが必要になるでしょう。
1.ChatGPTに問い合わせをした内容の正誤を判別する
先に書いた通り、ChatGPTはまだ『全幅の信頼をおける』ほどの完成度を持っていません。
時々間違えますし、間違える時には正誤の判断がわかりにくい間違え方をしたりします。
なのでその正誤の判断をしっかり出来るよう、正確な知識と判断力を鍛える必要があります。
2.ChatGPTが正確な意図を把握できるようにする
『ChatGPTに要件定義は向かない』というお話を先程しましたが、ChatGPTに出す指示そのものが、ある意味要件定義だとも言えます。
必要なもの・気をつけなければいけないこと・避けたほうがいいもの等をしっかりChatGPTに伝え、
もし回答に足らない箇所があるのなら、それを見つけ出して補足するような、そんな能力を身につけるべきでしょう。
3.日頃からChatGPTを使う
あとはとにかく使うことです。
何度もChatGPTを使うことで『何が得意なのか』『どういった点に気をつけなければならないか』といったChatGPTの輪郭が、この記事で書いた以上に見えてきます。
現在はGPT-4が最も有用と言えますが、これから更に優秀なAIや、プログラミングにチューニングされたAI等も出てくることでしょう。
ひょっとしたら今後数年で、プログラム環境は大きく変わるかもしれませんが、今触っておくことは決して無駄にはなりません。
ぜひまずは、ChatGPTに触れてみるところから始めてみてください。
お問合せ&各種リンク
お問合せ:GoogleForm
ホームページ:https://libproc.com
運営会社:TodoONada株式会社
Twitter:https://twitter.com/Todoonada_corp
Instagram:https://www.instagram.com/todoonada_corp/
Youtube:https://www.youtube.com/@todoonada_corp/
Tiktok:https://www.tiktok.com/@todoonada_corp
presented by

- この記事にいいね!する



この記事を書いた人


- 30いいね!
稼働ステータス
◎現在対応可能
- 土門 大貴
職種
エンジニア
システムエンジニア(SE)
希望時給単価
10,000円~30,000円
▼実績例 ・公共インフラ事業者様向け管理システム開発(Windows、Python、PostgreSQL) ・官公庁様向け地図情報アプリのインフラ開発(Windows、PostgreSQL) ・自治体様向けポイント管理サービスのAPI開発(Linux、PostgreSQL、JS、Python) ・大手製造業様向けクラウド環境開発支援(AWS全般、Terraform) ・公共事業様向け顔認証決算システム基盤開発(Windows、PostgreSQL、JS、Python) ・リース業様向け代理店向けWebAPI開発(AWS全般、GoLang、JS) ・通販サイトインフラ構築支援、要件定義~開発(AWS, ECCube) ・結婚相談所様向けオウンドメディア制作(WordPress、JS、ウェブディレクトションな)
スキル
Python
AWS
React
・・・(登録スキル数:6)
スキル
Python
AWS
React
・・・(登録スキル数:6)


